声明: 本文由( admin )原创编译,转载请保留链接: 做SEO优化必知robots协议规则大全
 2018网站优化发外链真的有用吗
2018网站优化发外链真的有用吗.jpg) 移动端网站内容图片显示不全实战优化
移动端网站内容图片显示不全实战优化 dede相关文章调用
dede相关文章调用 新浪博客引流营销操作方法大纲
新浪博客引流营销操作方法大纲 选择网站域名优化分析大全
选择网站域名优化分析大全 关键词排名下降
关键词排名下降 做网站优化必懂的FTP上传工具
做网站优化必懂的FTP上传工具 网站如何备案
网站如何备案
博主:墨沉 行业:互联网 品牌:墨沉SEO
我是周小雷 , 笔名"墨沉"
取自"腹中有墨,不愿沉沦"之意。
我一直有一颗90后浪漫主义者的心
梦里寻她千百度,蓦然回首,那人却在灯火阑珊处。
爱好互联网,写自传、现代诗词等。
小墨专注电子商务、武汉SEO优化、武汉SEO服务、武汉SEO顾问、微营销、淘宝运营、网站运营、网络营销、网络推广、微信公众号、营销系统研发和培训;小墨致力于帮助草根网络创业者打造最好的网络营销系统! 用思维改变命运!
小墨免费提供企业、论坛、博客等网站SEO服务诊断,欢迎大家咨询。墨沉SEO-微信:szjhke
或联系QQ:1194285866

 图片alt属性的SEO优化技巧
图片alt属性的SEO优化技巧 网站上放公司地址地图生成器网站友链对网站排名的作用
网站上放公司地址地图生成器网站友链对网站排名的作用.jpg) 网站SEO思维内链布局技巧及攻略
网站SEO思维内链布局技巧及攻略 火车头采集图片保存地址写法规则
火车头采集图片保存地址写法规则 strong标签使用
strong标签使用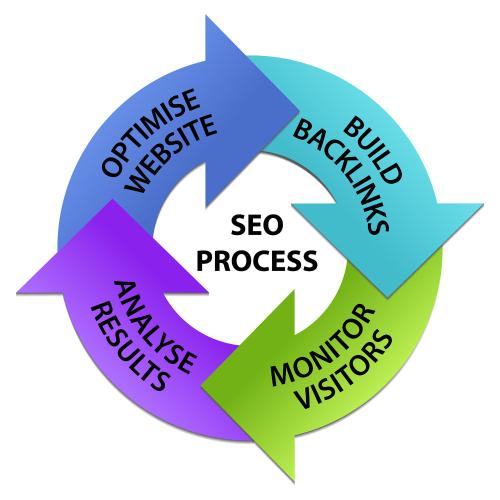 做SEO服务英文关键词大小写区分
做SEO服务英文关键词大小写区分 关键词优化分析,孝感seo教你分析定位
关键词优化分析,孝感seo教你分析定位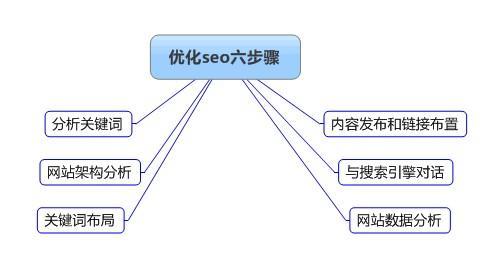 优化必杀技之"关键词"选择技巧
优化必杀技之"关键词"选择技巧.jpg) 二级目录建站,站内站翻页、上下一篇、面包屑链接改造
二级目录建站,站内站翻页、上下一篇、面包屑链接改造.jpg)

.jpg)


 采集:网站后台审核采集文章变更为当天生成日期及随机阅读量
采集:网站后台审核采集文章变更为当天生成日期及随机阅读量.jpg) 网站友情链接怎么做?
网站友情链接怎么做?.jpg) 网站文章缩略图指定文件夹里的图片调用
网站文章缩略图指定文件夹里的图片调用